The Document Object Model¶
The basic examples section introduced the findnodes() method
and XPath expressions for extracting parts of an XML document. For most
applications, that’s pretty much all you need, but sometimes it’s necessary to
use lower-level methods and to understand the relationships between different
parts of the document.
The XML::LibXML module implements Perl bindings for the W3C Document Object Model. The W3C DOM defines object classes, properties and methods for querying and manipulating the different parts of an XML (or HTML) document. In the Perl implementation, object properties are exposed via accessor methods.
Let’s start our exploration of the DOM with a simple XML document which
describes a book -
book.xml
1 2 3 4 5 6 7 8 9 10 | <?xml version='1.0' encoding='UTF-8' standalone="yes" ?>
<book edition="2">
<title>Training Your Pet Ferret</title>
<authors>
<author>Gerry Bucsis</author>
<author>Barbara Somerville</author>
</authors>
<isbn>9780764142239</isbn>
<dimensions width="162.56mm" height="195.58mm" depth="10.16mm" pages="96" />
</book>
|
When you ask XML::LibXML to parse the document, it creates an object to represent each part of the document and assembles those objects into a hierarchy as shown here:
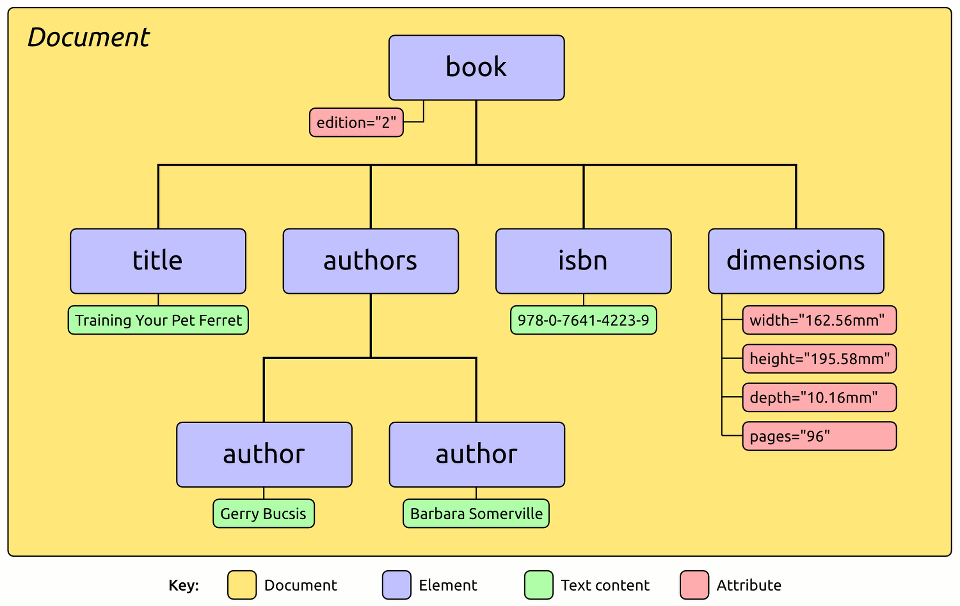
A simplified representation of the Document Object Model.
The source XML document has a <book> element which contains four other
elements: <title>, <authors>, <isbn> and <dimensions>. The
<authors> element in turn contains two <author> elements.
The hierarchy in the picture shows us that <book> has four “child”
elements. Similarly, <authors> has two child elements and one “parent”
element (<book>). Five of the elements have no child elements but four of
them do contain text content and one has some attributes.
The ‘Document’ object¶
When you parse a document with XML::LibXML the parser returns a ‘Document’ object - represented in yellow in the picture above. The reference documentation for the XML::LibXML::Document class lists methods you can use to interact with the document. The ‘Document’ class inherits from the ‘Node’ class so you’ll also need to refer to the docs for XML::LibXML::Node as well.
my $dom = XML::LibXML->load_xml(location => 'book.xml');
say '$dom is a ', ref($dom);
say '$dom->nodeName is: ', $dom->nodeName;
Output:
$dom is a XML::LibXML::Document
$dom->nodeName is: #document
The document object also provides methods you can use to extract information
from the XML declaration section - the very first line of the source XML,
which precedes the <book> element:
say 'XML Version is: ', $dom->version;
say 'Document encoding is: ', $dom->encoding;
my $is_or_not = $dom->standalone ? 'is' : 'is not';
say "Document $is_or_not standalone";
Output:
XML Version is: 1.0
Document encoding is: UTF-8
Document is standalone
You can serialise a whole DOM back out to XML by calling the toString()
method on the document object:
say "DOM as XML:\n", $dom->toString;
The document class also overrides the stringification operator, so if you simply treat the object as a string and print it out you’ll also get the serialised XML:
say "DOM as a string:\n", $dom;
‘Element’ objects¶
The blue boxes in the picture represent ‘Element’ nodes. The reference documentation for the XML::LibXML::Element class lists a number of methods, but like the ‘Document’ class, many more methods are inherited from XML::LibXML::Node.
Every XML document has one single top-level element known as the “document
element” that encloses all the other elements - in our example it’s the
<book> element. You can retrieve this element by calling the
documentElement() method on the document object and you can determine
what type of element it is by calling nodeName():
my $book = $dom->documentElement;
say '$book is a ', ref($book);
say '$book->nodeName is: ', $book->nodeName;
Output:
$book is a XML::LibXML::Element
$book->nodeName is: book
The <book> element has four child elements. You can use
getChildrenByTagName() to get a list of all the child elements with a
specific element name (this is not a recursive search, it only looks through
elements which are direct children):
my($isbn) = $book->getChildrenByTagName('isbn');
say '$isbn is a ', ref($isbn);
say '$isbn->nodeName is: ', $isbn->nodeName;
say '$isbn->to_literal returns: ', $isbn->to_literal;
say '$isbn stringifies to: ', $isbn;
Output:
$isbn is a XML::LibXML::Element
$isbn->nodeName is: isbn
$isbn->to_literal returns: 9780764142239
$isbn stringifies to: <isbn>9780764142239</isbn>
If you’re not looking for one specific type of element, you can get all the
children with childNodes():
my @children = $book->childNodes;
my $count = @children;
say "\$book has $count child nodes:";
my $i = 0;
foreach my $child (@children) {
say $i++, ": is a ", ref($child), ', name = ', $child->nodeName;
}
We already know that <book> contains four child elements, so you may be
a little surprised to see childNodes() returns a list of nine nodes:
$book has 9 child nodes:
0: is a XML::LibXML::Text, name = #text
1: is a XML::LibXML::Element, name = title
2: is a XML::LibXML::Text, name = #text
3: is a XML::LibXML::Element, name = authors
4: is a XML::LibXML::Text, name = #text
5: is a XML::LibXML::Element, name = isbn
6: is a XML::LibXML::Text, name = #text
7: is a XML::LibXML::Element, name = dimensions
8: is a XML::LibXML::Text, name = #text
If you refer back to the source XML document, you can see that after the
<book> tag and before the <title> tag there is some whitespace: a
line-feed character followed by two spaces at the start of the next line:
1 2 | <book edition="2">
<title>Training Your Pet Ferret</title>
|
These strings of whitespace are represented in the DOM by ‘Text’ nodes, which are children of the parent element. So a more accurate DOM diagram would look like this:
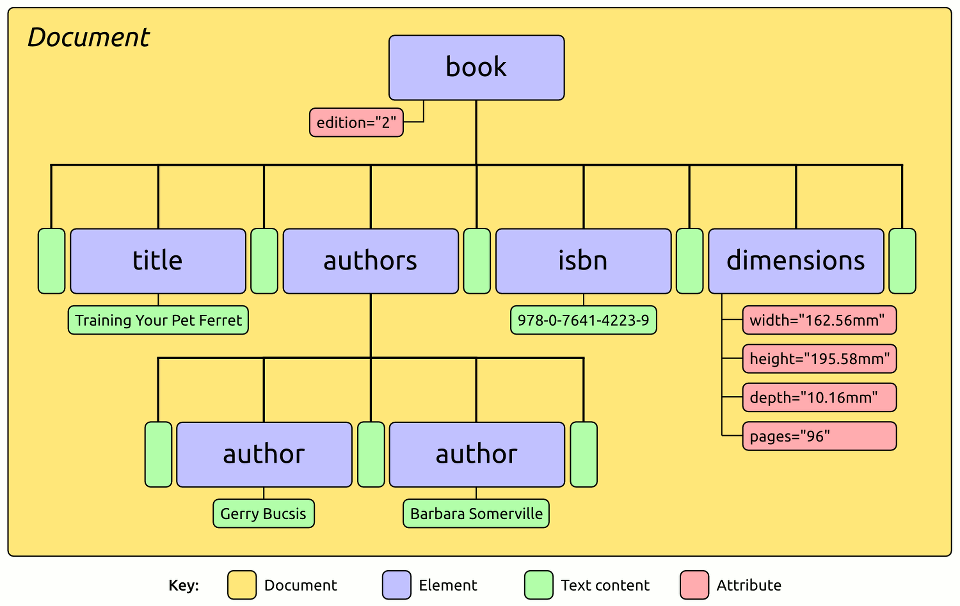
Document Object Model including whitespace-only text nodes
If you want to filter child nodes by type, XML::LibXML provides a number of constants which you can import when you load the module:
use XML::LibXML qw(:libxml);
And then you can compare $node->nodeType to these constants:
my @elements = grep { $_->nodeType == XML_ELEMENT_NODE } $book->childNodes;
$count = @elements;
say "\$book has $count child elements:";
$i = 0;
foreach my $child (@elements) {
say $i++, ": is a ", ref($child), ', name = ', $child->nodeName;
}
Output:
$book has 4 child elements:
0: is a XML::LibXML::Element, name = title
1: is a XML::LibXML::Element, name = authors
2: is a XML::LibXML::Element, name = isbn
3: is a XML::LibXML::Element, name = dimensions
That technique is useful for the general case of filtering child nodes by type,
but if you simply want to exclude text nodes that contain only whitespace, you
can do that by specifying the no_blanks option when parsing the source
document. This causes libxml to discard those ‘blank’ text nodes rather
than adding them into the DOM:
my $dom = XML::LibXML->load_xml(location => 'book.xml', no_blanks => 1);
Output:
$book has 4 child nodes:
0: is a XML::LibXML::Element, name = title
1: is a XML::LibXML::Element, name = authors
2: is a XML::LibXML::Element, name = isbn
3: is a XML::LibXML::Element, name = dimensions
Blank text nodes are really only a problem if you use the low-level DOM methods
for walking through child nodes. You’ll generally find that it’s much easier
to just use findnodes() and XPath Expressions to select exactly the elements or
other nodes you want. If the blank nodes don’t match your selector then they
won’t be returned in the result set.
‘Text’ objects¶
The green boxes in the picture represent ‘Text’ nodes. The reference documentation for the XML::LibXML::Text class lists a small number of methods and many more are inherited from the Node class.
There are numerous ways to get the text string out of a Text object but it’s important to be clear on whether you want the text as it appears in the XML (including any entity escaping) or whether you want the plain text that the source represents. Consider this tiny source document:
1 | <item>Fish & Chips</item>
|
And these different methods for accessing the text:
my $item = $dom->documentElement;
my($text) = $item->childNodes();
say '$text is a ', ref($text);
say '$text->data = ', $text->data;
say '$text->nodeValue = ', $text->nodeValue;
say '$text->to_literal = ', $text->to_literal;
say '$text->toString = ', $text->toString;
say '$text as a string: ', $text;
Producing this output:
$text is a XML::LibXML::Text
$text->data = Fish & Chips
$text->nodeValue = Fish & Chips
$text->to_literal = Fish & Chips
$text->toString = Fish & Chips
$text as a string: Fish & Chips
The data() and nodeValue() methods are essentially aliases. The
to_literal() method produces the same output via a more complex route, but
has the advantage that you can call it on any object in the DOM.
The toString() method is really only useful for serialising a whole DOM or
a DOM fragment out to XML. Stringification is particularly handy when you just
want to print an object out for debugging purposes.
‘Attr’ objects¶
The red boxes in the picture represent attributes. You’re unlikely to ever need to deal with attribute objects since it’s easier to get and set attribute values by calling methods on an Element object and passing in plain string values. An even easier approach is to use the tied hash interface that allows you to treat each element as if it were a hashref and access attribute values via hash keys:
my $book = $dom->documentElement;
my($dim) = $book->getChildrenByTagName('dimensions');
say '$dim->getAttribute("width") = ', $dim->getAttribute("width");
say "\$dim->{width} = $dim->{width}";
Output:
$dim->getAttribute("width") = 162.56mm
$dim->{width} = 162.56mm
The class name for the attribute objects is ‘Attr’ - the unfortunate truncation of the class name derives from the W3C DOM spec. The reference documentation is at: XML::LibXML::Attr. Some additional methods are inherited from the Node class but not all the Node methods work with Attr objects (once again due to behaviour specified by the W3C DOM).
# You probably don't need this object interface for attributes at all.
# The previous example showed how to access attributes directly via
# the Element object.
my $book = $dom->documentElement;
my($dim) = $book->getChildrenByTagName('dimensions');
my($width_attr) = $dim->getAttributeNode('width');
say '$width_attr is a ', ref($width_attr);
say '$width_attr->nodeName: ', $width_attr->nodeName;
say '$width_attr->value: ', $width_attr->value;
say '$width_attr as a string: ', $width_attr;
Output:
$width_attr is a XML::LibXML::Attr
$width_attr->nodeName: width
$width_attr->value: 162.56mm
$width_attr as a string: width="162.56mm"
‘NodeList’ objects¶
The ‘NodeList’ object is a part of the DOM that makes sense in DOM
implementations for other languages (e.g.: Java) but doesn’t make much sense in
Perl. Methods such as childNodes() or findnodes() that may need to
return multiple nodes, return a ‘NodeList’ object which contains the matching
nodes and allows the caller to iterate through the result set:
my $result = $book->childNodes;
say '$result is a ', ref($result);
my $i = 1;
foreach my $i (1..$result->size) {
my $node = $result->get_node($i);
say $node->nodeName if $node->nodeType == XML_ELEMENT_NODE;
}
Output:
$result is a XML::LibXML::NodeList
title
authors
isbn
dimensions
But things don’t need to be that complicated in Perl - if a method needs to return a list of values then it can just return a list of values. So the Perl bindings for DOM methods that would return a NodeList check the calling context. If called in a scalar context, they return a NodeList object (as above) but in a list context they just return the list of values - much simpler:
foreach my $node ($book->childNodes) {
say $node->nodeName if $node->nodeType == XML_ELEMENT_NODE;
}
When you execute a search that you expect should match exactly one node, take care to still use list context:
my($dim) = $book->findnodes('./dimensions');
say '$dim is a ', ref($dim);
say 'Page count: ', $dim->{pages};
Output:
$dim is a XML::LibXML::Element
Page count: 96
In this example, the assignment my($dim) = ... uses parentheses to force
list context, so findnodes() will return a list of Element nodes and the
first will be assigned to $dim. Without the parentheses, a NodeList would
be assigned to $dim.
If for some reason you find yourself with a NodeList object you can extract
the contents as a simple list with $result->get_nodelist.
The NodeList object does implement the to_literal() method, which returns
the text content of all the nodes, concatenated together as a single string.
If you need a list of individual string values, you can use
$result->to_literal_list():
say 'Authors: ', join ', ', $book->findnodes('.//author')->to_literal_list;
Output:
Authors: Gerry Bucsis, Barbara Somerville
Modifying the DOM¶
If you wish to modify the DOM, you can create new nodes and add them into the node hierarchy in the appropriate place. You can also modify, move and delete existing nodes. Let’s start with a simple XML document:
my $xml = q{
<record>
<event>Men's 100m</event>
</record>
};
my $dom = XML::LibXML->load_xml(string => $xml);
Navigate to the <event> element; change its text content; add an attribute
and print out the resulting XML:
my $record = $dom->documentElement;
my($event) = $record->getChildrenByTagName('event');
my $text = $event->firstChild;
$text->setData("Men's 100 metres");
$event->{type} = 'sprint';
say $dom->toString;
Output:
<?xml version="1.0"?>
<record>
<event type="sprint">Men's 100 metres</event>
</record>
You can use $dom->createElement to create a new element and then add it to
an existing node’s list of child nodes. You can append it to the end of the
list of children or insert it before/after a specific existing child:
my $country = $dom->createElement('country');
$country->appendText('Jamaica');
$record->appendChild($country);
my $athlete = $dom->createElement('athlete');
$athlete->appendText('Usain Bolt');
$record->insertBefore($athlete, $country);
say $dom->toString;
Output:
<?xml version="1.0"?>
<record>
<event type="sprint">Men's 100 metres</event>
<athlete>Usain Bolt</athlete><country>Jamaica</country></record>
Unfortunately that output is probably messier than you were expecting. To get
nicely indented XML output, you’d need to create text nodes containing a
newline and the appropriate number of spaces for indentation; and then add
those text nodes in before each new element. Or, an easier way would be to
pass the numeric value 1 to the toString() method as a flag indicating
that you’d like the output auto-indented:
say $dom->toString(1);
Output:
<?xml version="1.0"?>
<record>
<event type="sprint">Men's 100 metres</event>
<athlete>Usain Bolt</athlete><country>Jamaica</country></record>
But sadly that didn’t seem to work. The libxml library won’t add
indentation to ‘mixed content’ - an element whose list of child nodes
contains a mixture of both Element nodes and Text nodes. In this case the
<record> element contains mixed content (there’s a whitespace text node
before the <event> and another after it) so libxml does not try to
indent its contents.
If we strip out those extra text nodes then libxml will add indenting:
foreach my $node ($record->childNodes()) {
$record->removeChild($node) if $node->nodeType != XML_ELEMENT_NODE;
}
Output:
<?xml version="1.0"?>
<record>
<event type="sprint">Men's 100 metres</event>
<athlete>Usain Bolt</athlete>
<country>Jamaica</country>
</record>
While that did work, it required some rather specific knowledge of the document
structure. We were relying on knowing that all the text children of the
<record> element were whitespace-only and could be discarded. Here’s a
more generic approach which searches recursively through the document and
deletes every text node that contains only whitespace:
foreach ($dom->findnodes('//text()')) {
$_->parentNode->removeChild($_) unless /\S/;
}
That code is a little tricky so some explanation is probably in order:
- The loop does not declare a loop variable, so
$_is used implicitly. - The trailing
unlessclause runs a regex comparison against$_which implicitly callstoString()on the Text node. unless /\S/is a double negative which means “unless the text contains a non-whitespace character”.- the
removeChild()method needs to be called on the parent of the node we’re removing, so if the Text node is whitespace-only then we need to useparentNode().
Of course an even simpler solution in this case would have been to turn on the
no_blanks option (described earlier) when parsing the initial XML document.
Another handy method for adding to the DOM is appendWellBalancedChunk().
This method takes a string containing a fragment of XML. It must be well
balanced - each opening tag must have a matching closing tag and elements must
be properly nested. The XML fragment is parsed to create a
XML::LibXML::DocumentFragment which is then
appended to the target element:
$record->appendWellBalancedChunk(
'<time>9.58s</time><date>2009-08-16</date><location>Berlin, Germany</location>'
);
Output:
<?xml version="1.0"?>
<record>
<event type="sprint">Men's 100 metres</event>
<athlete>Usain Bolt</athlete>
<country>Jamaica</country>
<time>9.58s</time>
<date>2009-08-16</date>
<location>Berlin, Germany</location>
</record>
One ‘gotcha’ with the appendWellBalancedChunk() method is that the XML
parsing phase expects a string of bytes. So if you have a Perl string that
might contain non-ASCII characters, you first need to encode the character
string to a byte string in UTF-8 and then pass the byte string to
appendWellBalancedChunk():
my $byte_string = Encode::encode_utf8($perl_string);
$record->appendWellBalancedChunk($byte_string, 'UTF-8');
Creating a new Document¶
You can create a document from scratch by calling
XML::LibXML::Document->new() rather than parsing from an existing document.
Then use the methods discussed above to add elements and text content:
#!/usr/bin/perl
use 5.010;
use strict;
use warnings;
use autodie;
use XML::LibXML;
my $dom = XML::LibXML::Document->new('1.0', 'UTF-8');
my $title = $dom->createElement('title');
$title->appendText("Caf\x{e9} lunch: \x{20ac}12.50");
$dom->setDocumentElement($title);
my $filename = 'temp-utf8.xml';
open my $out, '>:raw', $filename;
In this example, the document encoding was declared as UTF-8 when the Document
object was created. Text content was added by calling appendText() and
passing it a normal Perl character string - which happened to contain some
non-ASCII characters. When opening the file for output it is not necessary to
use an encoding layer since the output from libxml will already be encoded
as utf-8 bytes.
The file contents look like this:
<?xml version="1.0" encoding="UTF-8"?>
<title>Café lunch: €12.50</title>
If we hex-dump the file we can see the e-acute character was written out as the 2-byte UTF-8
sequence C3 A9 and the euro symbol was written as a 3-byte UTF-8
sequence: E2 82 AC:
00000000: 3c3f 786d 6c20 7665 7273 696f 6e3d 2231 <?xml version="1
00000010: 2e30 2220 656e 636f 6469 6e67 3d22 5554 .0" encoding="UT
00000020: 462d 3822 3f3e 0a3c 7469 746c 653e 4361 F-8"?>.<title>Ca
00000030: 66c3 a920 6c75 6e63 683a 20e2 82ac 3132 f.. lunch: ...12
00000040: 2e35 303c 2f74 6974 6c65 3e0a .50</title>.
To output the document in a different encoding all you need to do is change the
second parameter passed to new() when creating the Document object. No
other code changes are required:
my $dom = XML::LibXML::Document->new('1.0', 'ISO8859-1');
This time when hex-dumping the file we can see the e-acute character was
written out as the single byte E9 and the euro symbol which cannot be
represented directly in Latin-1 was written in numeric character entity form
€:
00000000: 3c3f 786d 6c20 7665 7273 696f 6e3d 2231 <?xml version="1
00000010: 2e30 2220 656e 636f 6469 6e67 3d22 4953 .0" encoding="IS
00000020: 4f38 3835 392d 3122 3f3e 0a3c 7469 746c O8859-1"?>.<titl
00000030: 653e 4361 66e9 206c 756e 6368 3a20 2623 e>Caf. lunch: &#
00000040: 3833 3634 3b31 322e 3530 3c2f 7469 746c 8364;12.50</titl
00000050: 653e 0a e>.
If you’re generating XML from scratch then creating and assembling DOM nodes is
very fiddly and XML::LibXML might not be the best tool for the job.
XML::Generator is an excellent
module for generating XML - especially if you need to deal with namespaces.